目次
二分探索アルゴリズム
Pythonでソート済みの単語が列挙されたテキストファイルから、二分探索で高速に要素を検索する関数を作ったので置いておきます。操作回数がlogN以下となることを利用して、無限ループを回避しています。
def binary_search(target:str,words:list[str]) -> bool:
l:int = len(words)
left:int = 0
right:int = l-1
mid:int = (left+right)//2
i:int = 0
while i<math.log2(l):
if words[mid] == target:
print(words[mid])
return True
elif words[mid] > target:
right = mid
mid = (left+right)//2
else:
left = mid
mid = (left+right)//2
i += 1
return FalsePythonの標準探索と比較
pythonには指定した要素が集合の中に含まれているかどうかを確認する in, not inというものがあります。
この時の要素の探索には、線形探索を使っていると考えられます。(非ソート済みの集合の場合、二分探索は使えないため。)
そこで、実際に両者の探索にかかる実行時間を比較してみることにしました。
探索条件
・約30万語のソート済みの単語リストを用意。
・インデックス0から末要素までの探索にかかる時間をそれぞれの方法で記録し、その差分をプロット。
ただし、全要素を探索していると時間がかかるので、今回は1000要素ごとに結果を抽出します。
コード
import time
import math
from tqdm import tqdm
import matplotlib.pyplot as plt
def binary_search(target,words):
l = len(words)
left = 0
right = l-1
mid = (left+right)//2
i = 0
while i<=math.log2(l):
if words[mid] == target:
return True
elif words[mid] > target:
right = mid
mid = (left+right)//2
else:
left = mid
mid = (left+right)//2
i += 1
return False
with open('words.txt','r') as fp:
words = [i.replace("\n","") for i in fp.readlines()]
fig = plt.figure()
plt.grid()
plt.xlabel("i")
plt.ylabel("t1-t2")
for i in tqdm(range(0,len(words),100)):
target = words[i]
ts = time.time()
S1 = binary_search(target,words)
t1 = time.time() - ts
ts = time.time()
S2 = target in words
t2 = time.time() - ts
if S1 != S2:
break
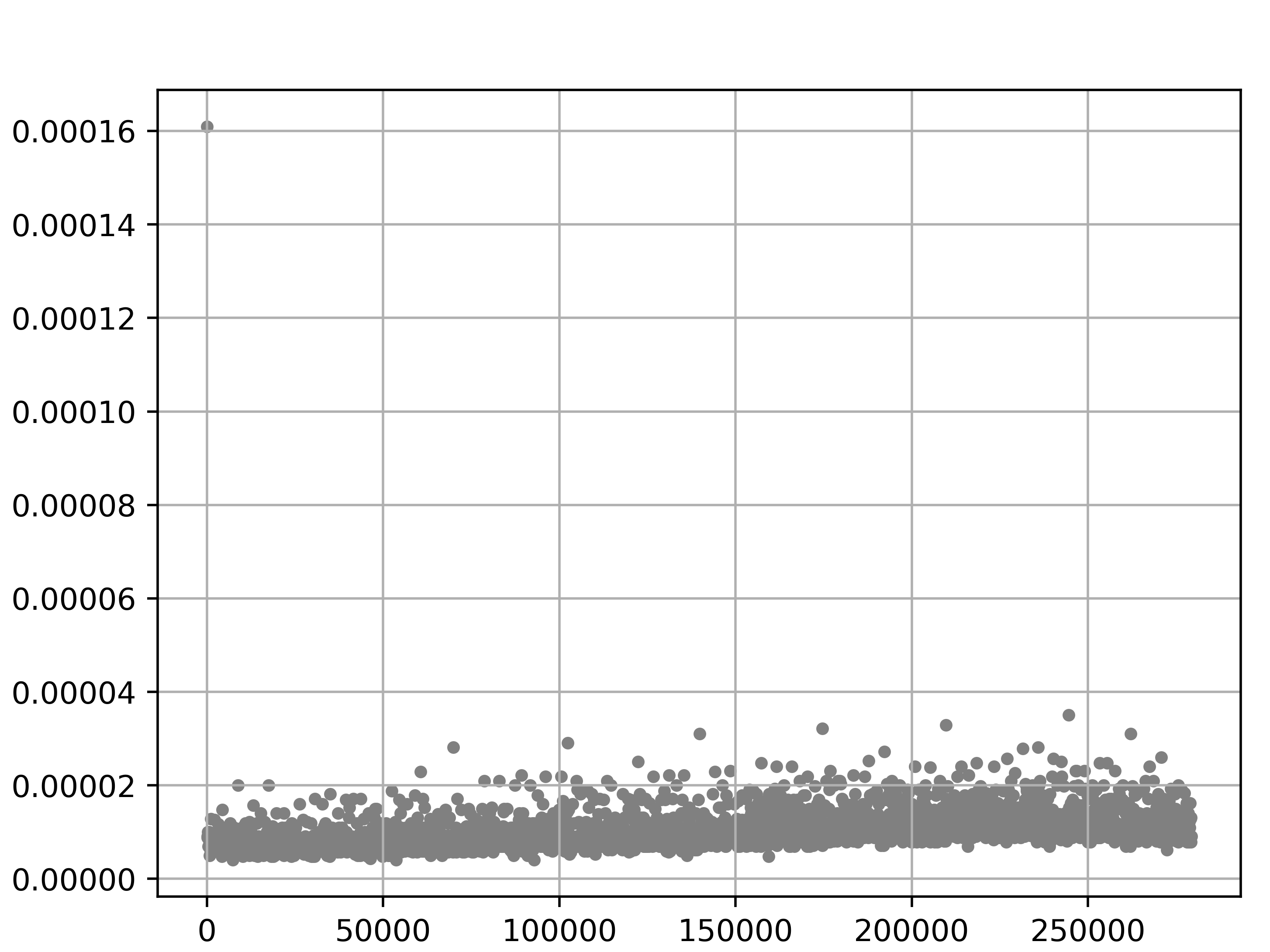
plt.scatter(i,t1-t2,s=10,color = "gray")
fig.savefig("test1.png",dpi = 500)実行結果
t1-t2
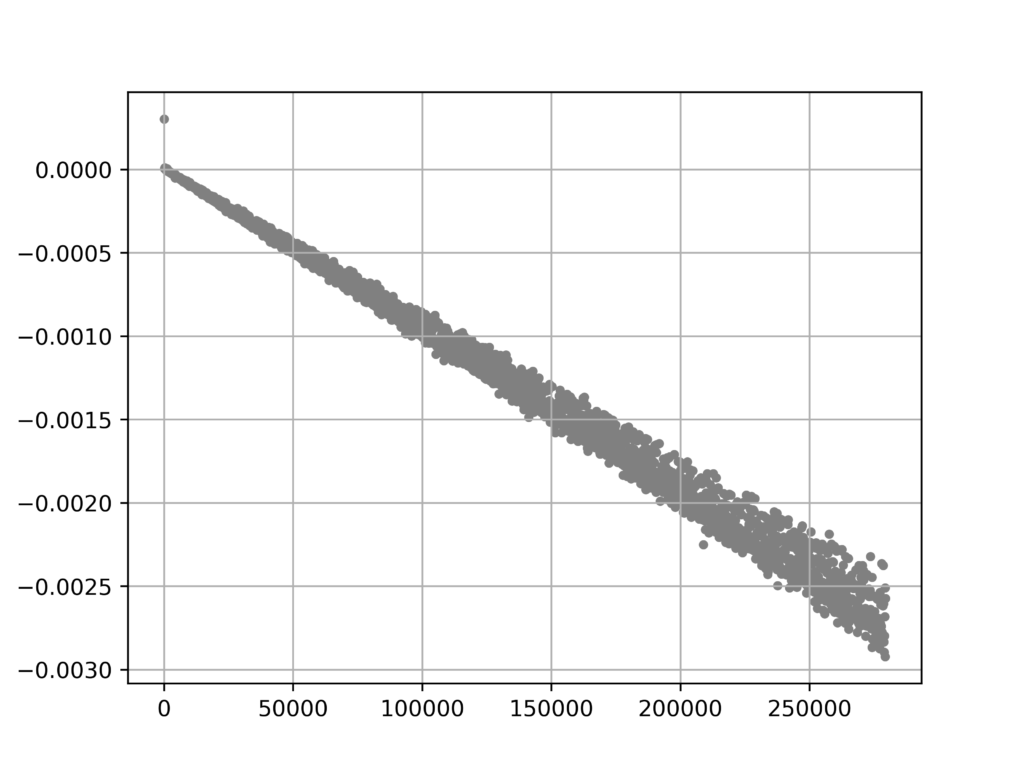
線形探索にかかった時間(t2)
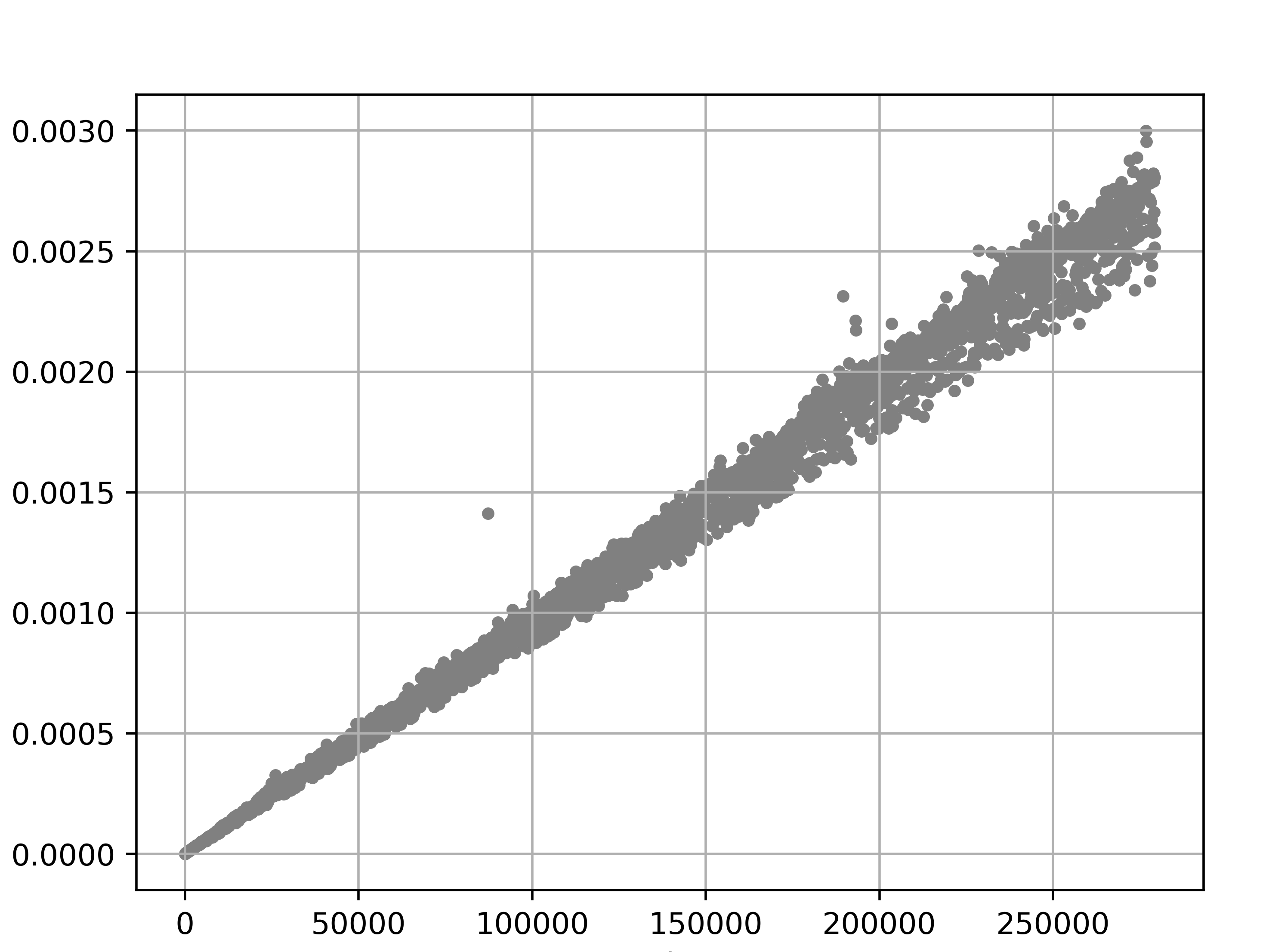
二分探索にかかった時間(t1)