

これまではFastAPIを使用してデータをSQLite形式で取り扱っていましたが、今回は本格的にサーバーに展開できるようにMaria DBに切り替えていきます。また、データベースのcrud操作を非同期処理に切り替えます。
具体的には、以下の記事で作成したユーザーの登録センテンスに対するマルコフ連鎖を抽出するアプリケーションをMariaDB+非同期処理に書き換えていきます。
目次
データベースへの接続(database.py)
import os
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from typing import cast, Callable, AsyncContextManager
mariadb_user: str = os.environ["MARIADB_USER"]
mariadb_password: str = os.environ["MARIADB_PASSWORD"]
mariadb_database: str = os.environ["MARIADB_DATABASE"]
SQLALCHEMY_DATABASE_URL = f"mariadb+asyncmy://{mariadb_user}:{mariadb_password}@db/{mariadb_database}?charset=utf8mb4"
engine = create_async_engine(SQLALCHEMY_DATABASE_URL, pool_recycle=3600)
SessionLocal = cast(
Callable[[], AsyncContextManager[AsyncSession]],
sessionmaker(
engine, future=True, autocommit=False, autoflush=False, class_=AsyncSession
)
)
Base = declarative_base()コンテナでのapt-get
コンテナ上に直接モジュールをインストールします。
今回はgraphvizというグラフ描画モジュールをインストールする必要がありました。
dockerfileに以下の文を足します。
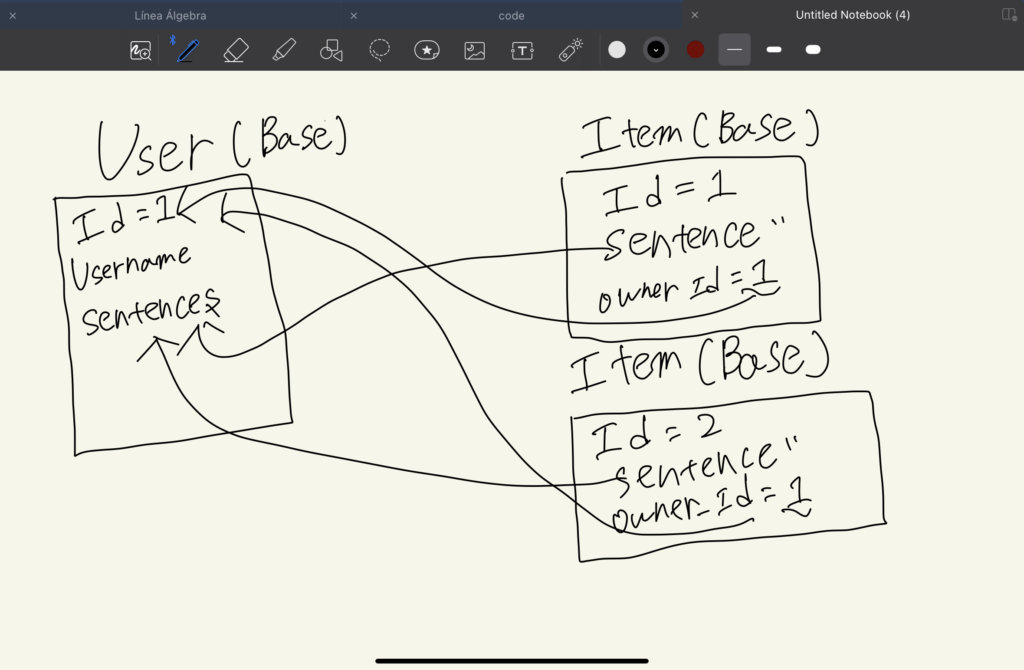
RUN apt-get update && export DEBIAN_FRONTEND=noninteractive && apt-get -y install --no-install-recommends <module name>データベースのベースモデル(models.py)
モデルはSQLite3の時と全く同じにしました。
from sqlalchemy import Column, ForeignKey, Integer, String, Text
from sqlalchemy.orm import relationship
from .database import Base
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True, autoincrement=True)
username = Column(String(100), unique=True, index=True)
sentences = relationship("Item", back_populates="owner", lazy="selectin")
class Item(Base):
__tablename__ = "sentences"
id = Column(Integer, primary_key=True, index=True, autoincrement=True)
sentence = Column(Text, index=True)
owner_id = Column(Integer, ForeignKey("users.id"))
owner = relationship("User", back_populates="sentences", lazy="joined")
図にするとこのような感じ。
schemas.pyの定義
こちらも、以前の記事から変更はありません。
from typing import List, Optional
from pydantic import BaseModel
class ItemBase(BaseModel):
sentence: str
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
username: str
class UserCreate(UserBase):
pass
class User(UserBase):
id: int
sentences: List[Item] = []
class Config:
orm_mode = True
crud処理の非同期化
関数名の前にasyncを付けます。また、データの読み込みなど非同期処理ができそうな箇所にawaitを付けます。
from sqlalchemy.orm import Session
from . import models
from . import schemas
from sqlalchemy.future import select
async def get_user(db: Session, user_id: int):
return (await db.scalars(select(models.User).where(models.User.id == user_id))).first()
async def get_sentences(db: Session,user_id: int) -> list[models.Item]:
stmt = select(models.Item).order_by(models.Item.id).where(models.Item.owner_id == user_id)
items: list[models.Item] = (await db.scalars(stmt)).all()
return items
async def get_user_by_username(db: Session, username: str):
return (await db.scalars(select(models.User).where(models.User.username == username))).first()
async def get_users(db: Session, skip: int = 0, limit: int = 100):
return (await db.scalars(select(models.User).offset(skip).limit(limit))).all()
async def create_user(db: Session, user: schemas.UserCreate):
db_user = models.User(username = user.username)
db.add(db_user)
await db.commit()
await db.refresh(db_user)
return db_user
async def get_sentences_all(db: Session, skip: int = 0, limit: int = 100):
return (await db.scalars(select(models.Item).offset(skip).limit(limit))).all()
async def create_user_sentence(db: Session, sentence: schemas.ItemCreate, user_id: int):
db_sentence = models.Item(**sentence.dict(), owner_id=user_id)
db.add(db_sentence)
await db.commit()
await db.refresh(db_sentence)
return db_sentence
非同期の場合は処理内容を逐一実行しているとおかしなことになるので、大きな処理(今回はマルコフ連鎖の抽出)は関数にまとめてawaitを付け加えて実行する形にします。
from graphviz import Digraph
def temp(sentences,user_id):
sentences = [i.sentence for i in sentences]
words = [i.lower() for i in '\n'.join(sentences).split()]
chain = {i: [] for i in words}
for i in [[words[i], words[i+1]] for i in range(len(words)-1)]:
chain[i[0]].append(i[1])
chain = {i: chain[i] for i in chain if i[-1] != "." and i[-1] != ","}
edges = {(i, j): str(1/len(list(set(chain[i]))))[:4] if len(
chain[i]) != 0 else "0" for i in chain for j in chain[i]}
G = Digraph(format="png")
G.attr("node", shape="circle")
for i, j in edges:
G.edge(str(i), str(j), label=edges[(i, j)])
text = "".join([str(i) for i in G.source])
edges_json = [i.replace("\n", '').replace('}', '')
for i in text.split('\t')][2:]
G.render(f"markov{user_id}")
return edges_jsonmain.py
クラッド処理を統合します。
import asyncio
from fastapi import FastAPI, HTTPException
from fastapi.staticfiles import StaticFiles
# from .utils.spa_staticfiles import SPAStaticFiles # For StaticFiles for SPA (React, Vue, etc.)
from .schemas import ItemCreate
from typing import List
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
from . import crud
from .import models
from .import schemas
from .database import SessionLocal, engine
from graphviz import Digraph
import json
from fastapi.responses import FileResponse
from .functioins import temp
app = FastAPI()
async def get_db():
async with SessionLocal() as db:
yield db
@app.on_event("startup")
async def startup_event():
async with engine.begin() as conn:
# Create DB tables.
await conn.run_sync(models.Base.metadata.create_all)
@app.post("/users/", response_model=schemas.User)
async def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = await crud.get_user_by_username(db, username=user.username)
if db_user:
raise HTTPException(status_code=400, detail="Username already taken.")
return await crud.create_user(db=db, user=user)
@app.get("/users/", response_model=List[schemas.User])
async def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = await crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
async def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = await crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found.")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
async def create_sentence_for_user(
user_id: int, sentence: schemas.ItemCreate, db: Session = Depends(get_db)
):
return await crud.create_user_sentence(db=db, sentence=sentence, user_id=user_id)
@app.get("/users/sentences/{user_id}", response_model=schemas.User)
async def read_sentences(user_id: int, db: Session = Depends(get_db)):
sentences = await crud.get_sentences(db=db, user_id=user_id)
print(sentences)
return await crud.get_user(db, user_id=user_id)
@app.get("/users/markovchain/{user_id}")
async def generate_chain(user_id: int, db: Session = Depends(get_db)):
sentences = await crud.get_sentences(db=db, user_id=user_id)
edges_json = await asyncio.to_thread(temp, sentences, user_id)
return {str(user_id): json.dumps(edges_json)}
@app.get("/image/{user_id}")
async def get_image(user_id: int):
return FileResponse(f"markov{user_id}.png")
