この記事では、文章に対するマルコフ連鎖を抽出した後、Graphvizを使用して単語の遷移を確率付きで可視化します。
目次
サンプルテキスト
以下の文章を使用します。
So shaken as we are, so wan with care.
Find we a time for frighted peace to pant,
And breathe short-winded accents of new broils
To be commenced in strands afar remote.
No more the thirsty entrance of this soil
Shall daub her lips with her own children’s blood;
Nor more shall trenching war channel her fields,
Nor bruise her flowerets with the armed hoofs
Of hostile paces: those opposed eyes,二階マルコフ連鎖の抽出
二階までならイテラティブな方法で簡単にできます。
def markov_2th(src) -> dict:
words_count = {}
words = [i.lower() for i in open(src).read().split()]
for i in words:
if i not in words_count:
words_count[i] = words.count(i)
w_adj = {i:[] for i in words}
for i in [[words[i],words[i+1]] for i in range(len(words)-1)]:
w_adj[i[0]].append(i[1])
return w_adj
chain = markov_2th("s.txt")
print(chain)
graphvizによる可視化
graphvizは前後の関係を定義するだけで、後は自動で可視化してくれます。
edges = {(i,j):str(1/len(list(set(chain[i]))))[:4] if len(chain[i]) !=0 else "0" for i in chain for j in chain[i]}
G = Digraph(format="png")
G.attr("node", shape="circle")
n = 0
for i,j in edges:
G.edge(str(i), str(j),label=edges[(i,j)])
n+=1
G.render("markov")実行結果
画面が縦長すぎたので分割しました。

次はシンプルな文章でやってみます。
I like a dog.
I like dogs.
I like a cat.
I like cats.
I like the cat.
I like the dog.
I like the cats.
I like the dogs.
She likes a dog.
She likes dogs.
She likes a cat.
She likes cats.
She likes the cat.
She likes the dog.
She likes the cats.
She likes the dogs.
I don't like it.実行結果
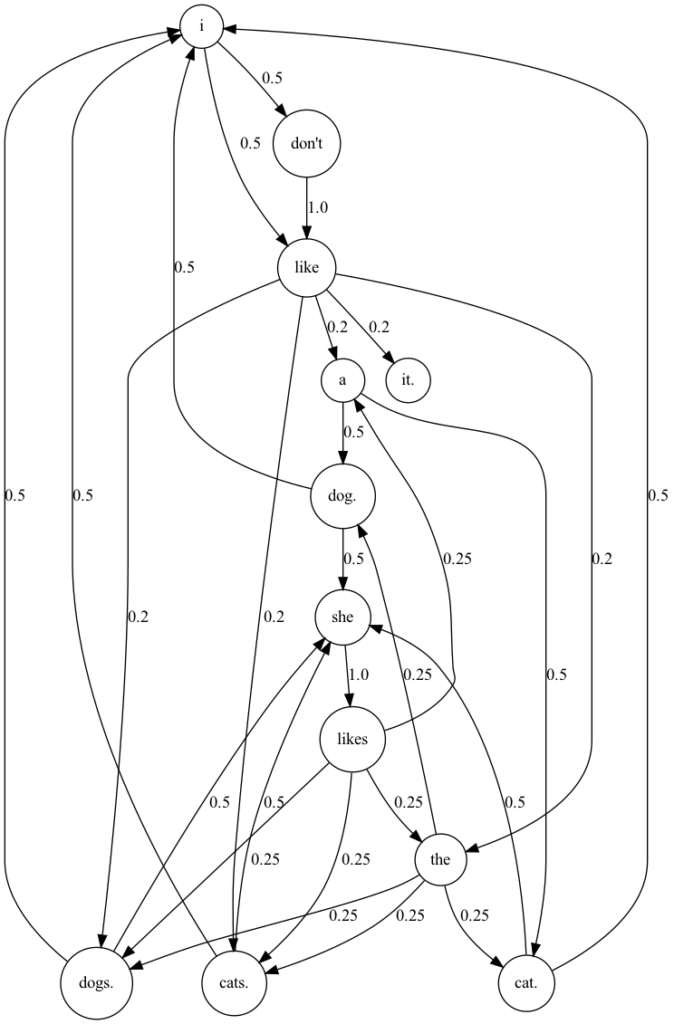
センテンスごとにマルコフ連鎖を抽出
例えば、直前の画像を見ると、ピリオドがある単語にも次の単語が接続されている箇所があると思います。これは、テキストファイルを一つの大きな文章として見ていることが原因です。そこで、各センテンスごとに単語の関係性を抽出できるようにコードを書き換えてみます。
chain = markov_2th("a.txt")
chain = {i:chain[i] for i in chain if i[-1] != "." and i[-1] != ","}
edges = {(i,j):str(1/len(list(set(chain[i]))))[:4] if len(chain[i]) !=0 else "0" for i in chain for j in chain[i]}
G = Digraph(format="png")
G.attr("node", shape="circle")
n = 0
for i,j in edges:
G.edge(str(i), str(j),label=edges[(i,j)])
n+=1
G.render("markov")実行結果
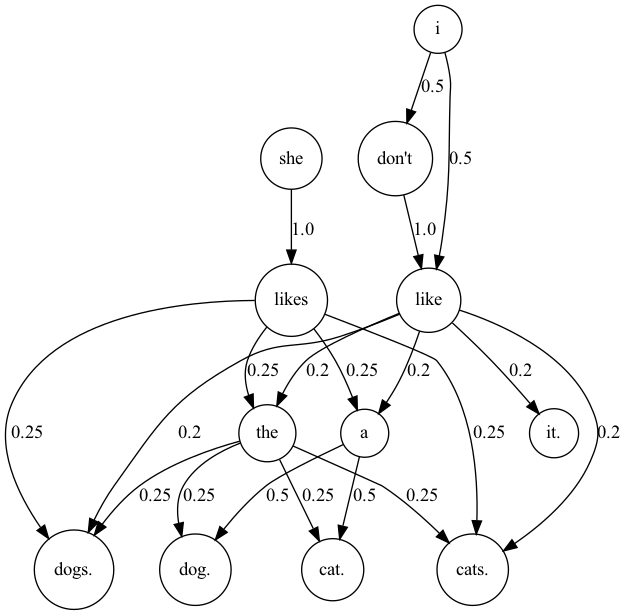
他の言語で実行
スペイン語
ほぼ英語と同じですがやってみます。
me gusta el gato.
me gusta la jirafa.
me gustan los gatos.
me gustan los perros.
le gusta el gato.
le gusta el perro.
le gustan los gatos.
le gustan los perros.
no me gusta el gato.
no me gustan los perros.
no le gusta el gato.
no le gustan los perros.
me gusta la jirafa.
nos gustan las conejas.実行結果
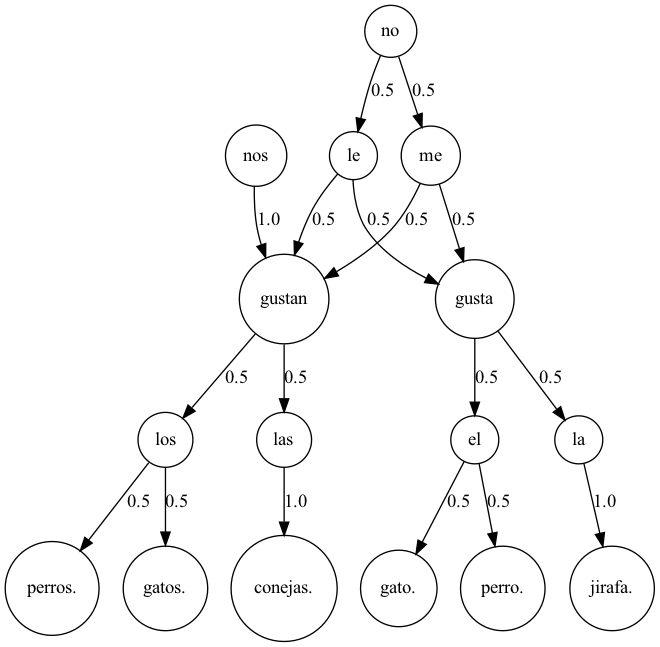
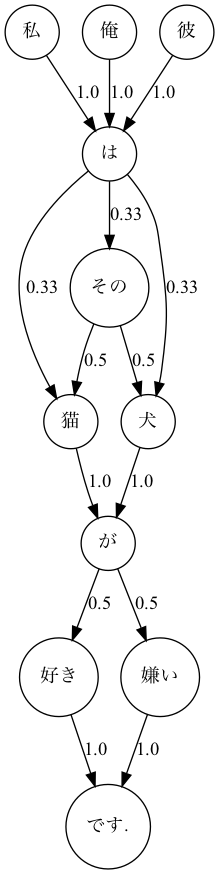
日本語
日本語は文字の間に区切りがないので、形態素解析を行います。
例えば以下のような文章があったとします。
私は猫が好きです。
私は犬が好きです。
私はその猫が好きです。
私はその犬が好きです。
俺は猫が好きです。
俺は犬が好きです。
俺はその猫が好きです。
俺はその犬が好きです。
私は犬が嫌いです。
私は猫が嫌いです。
彼は犬が嫌いです。
彼は犬が好きです。このままでは文の切れ目が分からないため、janomeを使用して分かち書きを行います。
import janome
# -*- coding: utf-8 -*-
import janome.tokenizer
def extract(text) -> str:
s = ""
tokenizer = janome.tokenizer.Tokenizer()
for t in list(tokenizer.tokenize(text)):
s+= str(t).split("\t")[0] + " "
return s.replace(" 。",".") +'\n'
with open("a.txt") as f:
with open("s.txt","w") as w:
for i in f.readlines():
w.write(extract(i))実行結果
私 は 猫 が 好き です.
私 は 犬 が 好き です.
私 は その 猫 が 好き です.
私 は その 犬 が 好き です.
俺 は 猫 が 好き です.
俺 は 犬 が 好き です.
俺 は その 猫 が 好き です.
俺 は その 犬 が 好き です.
私 は 犬 が 嫌い です.
私 は 猫 が 嫌い です.
彼 は 犬 が 嫌い です.
彼 は 犬 が 好き です. このファイルを読み込んで、可視化して見ます。
実行結果